
[Python Note] 넘파이(NumPy) 이해하기 (4)
1. 난수 생성
- random 즉, 무작위로 값을 발생시킨다.
- 어떤 알고리즘에 의해 난수처럼 보이는 수열을 생성한다.
1) 시드 설정
- 난수를 생성할 때 시드(seed)를 고정하면 다시 실행해도 같은 난수들이 생성된다.
np.random.seed(n)을 통해 설정할 수 있다.
2) 난수 생성
- 난수를 많이 생성할수록 그 분포에 가까워진다.
균등분포($U(0,1)$)에서 생성
-
np.random.rand(arr.shape)/np.random.random(size=arr.shape)
입력한 배열의 크기에 맞게 $0\leq x<1$ 인 $x$를 랜덤하게 추출한다.
두 함수 다 같은 기능이지만 input하는 방식이 다르다.np.random.seed(0) np.random.rand(2, 3) np.random.random(size=(2,3))array([[0.5488135 , 0.71518937, 0.60276338], [0.54488318, 0.4236548 , 0.64589411]]) array([[0.43758721, 0.891773 , 0.96366276], [0.38344152, 0.79172504, 0.52889492]])
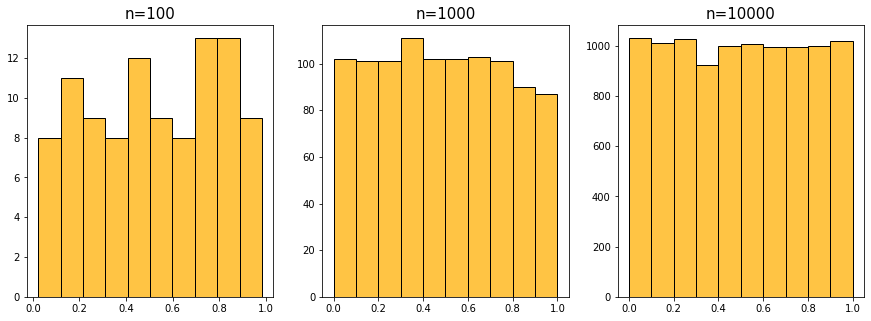
$U(a,b)$인 균등분포에서 난수생성하기(Click!)
\[ a \leq x < b \quad\rightarrow\quad 0 \leq x - a < b - a \quad\rightarrow\quad 0 \leq u = \dfrac{x-a}{b-a} < 1 \quad\Rightarrow\quad x = u\times (b-a) + a \]
a = 3
b = 7
u = np.random.rand(10)
x = (b-a)*u + a
x
array([6.16690015, 5.11557968, 5.27217824, 6.70238655, 3.28414423,
3.3485172 , 3.08087359, 6.33047938, 6.112627 , 6.48004859])
표준정규분포($N(0,1)$)에서 생성
np.random.randn(arr.shape)
입력한 배열의 크기에 맞게 표준정규분포에서 $x$를 랜덤하게 추출한다. \[ f(z) = \dfrac{1}{\sqrt{2\pi}}e^{-\frac{z^2}{2}},\quad -\infty < z < \infty \]
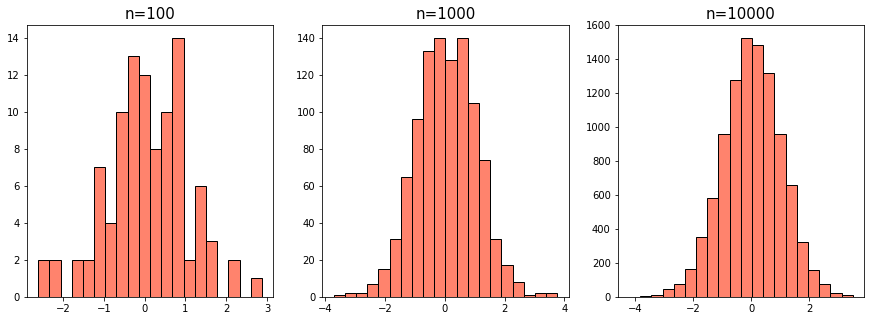
$N(\mu,\sigma^2)$인 정규분포에서 난수 생성하기(Click!)
\[ f(x) = \dfrac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\dfrac{(x-\mu)^2}{2\sigma^2}\right),\quad Z = \dfrac{X - \mu}{\sigma} \quad\Rightarrow\quad X = \mu + Z\sigma \]
np.random.normal(mu, sigma, size=arr.shape)를 사용할 수도 있다.
mu = 5
sigma = 2
z = np.random.randn(10000)
x = mu + z*sigma
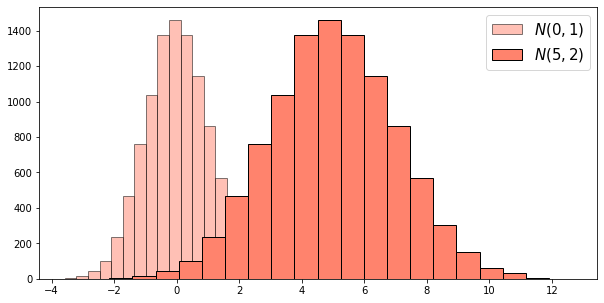
3) 정수 생성
-
np.random.randint(a, b, size=arr.shape)
size에 맞게 $a\leq x<b$ 인 정수 $x$를 랜덤하게 추출한다.np.random.randint(1,10, size=(3, 4))array([[9, 5, 6, 2], [2, 8, 5, 6], [1, 2, 8, 2]])
2. 데이터 샘플링
1) 복원 추출 / 비복원 추출(Sampling)
np.random.choice(arr, size=n, replace=True or False, p)
배열arr의 원소들 중n개를 뽑는데 가중치를p로 해서 복원추출(replace=True) 또는 비복원추출(replace=False)한다.복원 추출 vs 비복원 추출
- 복원 추출(with replacement)
상자에서 공을 뽑고 숫자를 확인한 후 다시 넣고 뽑는다. - 비복원 추출(without replacement)
상자에서 공을 뽑고 숫자를 확인한 후 다시 넣지 않고 남은 것에서 뽑는다.
- 복원 추출(with replacement)
2) 데이터 셔플(Shuffle)
np.random.shuffle(arr)
배열arr의 원소 순서를 섞는다. 자체가 출력되지 않고, 기존의 배열이 바뀐다.
arr1 = np.arange(10)
print(np.random.choice(arr1, size=5, replace=True)) # 복원 추출
print(np.random.choice(arr1, size=5, replace=False)) # 비복원 추출
print(np.random.shuffle(arr1)) # 셔플
print(arr1)
[2 9 6 8 2]
[6 5 2 0 4]
None
[1 2 4 0 7 6 8 5 3 9]
3. 빈도표 생성
- 여러 개의 난수를 발생했을 때 특정 구간에 있는 개수를 통해 데이터가 어디에 더 많이 분포되어 있는지 파악할 수 있다.
np.unique(arr, return_counts=True or False)
배열arr의 중복되지 않은 값을 출력하며,return_counts=True를 하면 해당되는 값의 중복 수도 함께 출력한다.
결과값의 type은 리스트가 아닌 numpy의 배열이다.np.bincount(arr)
배열arr의 빈도수를 출력한다.
결과값의 type은 리스트가 아닌 numpy의 배열이다.
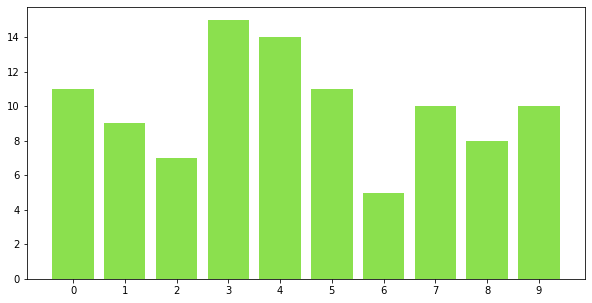
import numpy as np
np.random.seed(0)
arr1 = np.random.randint(0,10, size = 100)
print(np.unique(arr1))
print(np.unique(arr1, return_counts=True))
print(np.bincount(arr1))
[0 1 2 3 4 5 6 7 8 9]
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),
array([11, 9, 7, 15, 14, 11, 5, 10, 8, 10], dtype=int64))
[11 9 7 15 14 11 5 10 8 10]


댓글남기기