
[Python Note] 판다스(Pandas) 이해하기 (1)
1. 시리즈(Series) 생성
시리즈(Series) Class는 데이터인 값(value)과 데이터의 이름을 의미하는 인덱스(index)를 함께 표현한 것이다.
- 모듈 불러오기:
import pandas as pd
pd.Series(a, index='index.name', name='name', dtype='dtype')
- 이때
a는 리스트(list), 튜플(tuple), 배열(np.array)이 가능하다. series.index로 시리즈의 인덱스를 출력/설정할 수 있다.series.values로 시리즈의 값을 출력/설정할 수 있다.series.name으로 시리즈의 이름을 출력/설정할 수 있다.series.index.name으로 시리즈의 인덱스 이름을 설정할 수 있다.
다음 예제는 나무위키에 있는 짱구는 못말려 친구들의 프로필을 참고하였다.
| 해바라기반 | 키(cm) | 몸무게(kg) | 혈액형 |
|---|---|---|---|
| 신짱구 | 105.9 | 22.8 | B |
| 김철수 | 108.7 | 20.7 | O |
| 한유리 | 104.2 | 14 | B |
| 이훈이 | 106.2 | 20 | A |
| 맹구 | 113.9 | 25 | AB |
여기에서 해바라기반 친구들의 이름이 index가 되고, ‘키(cm)’, ‘몸무게(kg)’, ‘혈액형’ 열이 각각의 value가 된다.
import pandas as pd
height = np.array([105.9, 108.7, 104.2, 106.2, 113.9]) # 배열
weight = [22.8, 20.7, 14, 20, 25] # 리스트
blood_type = ('B', 'O', 'B', 'A', 'AB') # 튜플
idx = ['신짱구', '김철수', '한유리', '이훈이', '맹구']
S1 = pd.Series(height, index=idx, name='키(cm)')
S1.index.name = '해바라기반'
S2 = pd.Series(weight, index=idx)
S2.name = '몸무게(kg)'
S2.index.name = '해바라기반'
S3 = pd.Series(blood_type)
S3.name = '혈액형'
S3.index = idx
S3.index.name = '해바라기반'

- 인덱스(index)와 값(value)를 함께 쓰는 딕셔너리(dictionary)로도 생성할 수 있다.
-
series.items()를 하면 시리즈를 zip type으로 바꿀 수 있다. 그래서dict()함수를 통해 딕셔너리형으로 바꿀 수 있다.S1_dict = {'신짱구': 105.9, '김철수': 108.7, '한유리': 104.2, '이훈이': 106.2, '맹구': 113.9} S1 = pd.Series(S1_dict, name='몸무게(kg)') print(list(S1.items())) print(dict(S1.items()))[('신짱구', 105.9), ('김철수', 108.7), ('한유리', 104.2), ('이훈이', 106.2), ('맹구', 113.9)] {'신짱구': 105.9, '김철수': 108.7, '한유리': 104.2, '이훈이': 106.2, '맹구': 113.9} -
대부분 자동으로 dtype를 적절하게 잘 잡아주지만 그렇지 않은 경우 직접 설정할 수 있다. 나중에 변경할 때에는
series.astype()함수를 이용한다.
예를 들어 ‘혈액형’열의 현재 dtype이 object이므로 string으로 변경하고자 할 때, 다음과 같이 진행한다.※ 이때
astype()은 변경해서 출력할 뿐S3에 저장되지는 않는다.
S3에 저장하고 싶을 때에는 다시 덮어씌워야 한다.S3.astype('string')해바라기반 신짱구 B 김철수 O 한유리 B 이훈이 A 맹구 AB Name: 혈액형, dtype: string
2. 수정 / 추가 / 삭제
- 수정: 짱구의 키를 다시 재보니 107.5cm였다고 하자.
- 추가: 해바라기 반에 ‘한수지’ 친구가 전학을 왔다고 하자.
친구의 정보를 추가해보자.(‘한수지’, 몸무게: 12.4kg) - 삭제: 전산오류로 인해 훈이의 혈액형 정보가 삭제되었다고 하자.
# 수정
S1['신짱구'] = 107.5
# 추가
S2.한수지 = 'O'
# 삭제
del S3['이훈이']

3. 인덱싱(indexing) / 슬라이싱(Slicing)
- 인덱싱과 슬라이싱은 위치 또는 인덱스명으로 가능하다.
- 인덱스명을 통해 자료의 순서를 쉽게 바꿀 수도 있다.
인덱스를 여러 개 지정할 때에는 리스트로 표현한다.
1)의 시리즈 데이터에서 추출하였다.
# Q1. 철수의 키는?
print('Q1\n김철수의 키(인덱스 이용) >', S1.김철수)
print('김철수의 키(위치 이용) >', S1[1], end='\n\n')
# Q2. 짱구부터 유리까지의 몸무게는?
print('Q2\n',S2['신짱구':'한유리'], end='\n\n')
# Q3. 유리와 훈이의 키는?
print('Q3\n',S1[['한유리', '이훈이']], end='\n\n')
# Q4. 몸무게가 20kg 넘는 친구들은?
print('Q4\n',S2[S2 >= 20], end='\n\n')
# Q5. 혈액형 시리즈, 한유리 > 신짱구 > 맹구 > 김철수 > 이훈이 순으로 바꾸기
print('Q5\n',S3[['한유리', '신짱구', '맹구', '김철수', '이훈이']], end='\n\n')
# Q6. 키 시리즈, 맹구 > 이훈이 > 한유리 > 김철수 > 신짱구 순으로 바꾸기
print('Q6\n',S1[S1.index[::-1]])
Output
Q1
김철수의 키(인덱스 이용) > 108.7
김철수의 키(위치 이용) > 108.7
Q2
해바라기반
신짱구 22.8
김철수 20.7
한유리 14.0
Name: 몸무게(kg), dtype: float64
Q3
해바라기반
한유리 104.2
이훈이 106.2
Name: 키(cm), dtype: float64
Q4
해바라기반
신짱구 22.8
김철수 20.7
이훈이 20.0
맹구 25.0
Name: 몸무게(kg), dtype: float64
Q5
해바라기반
한유리 B
신짱구 B
맹구 AB
김철수 O
이훈이 A
Name: 혈액형, dtype: object
Q6
해바라기반
맹구 113.9
이훈이 106.2
한유리 104.2
김철수 108.7
신짱구 105.9
Name: 키(cm), dtype: float64
4. 연산 / 정렬
- 기본 연산은 Numpy에서의 연산과 같다. 그러나 연산의 대상인 시리즈의 인덱스가 일치한 경우에만 연산이 가능하다.
- 인덱스명이 다른 경우에는 계산되지 않고,
NaN으로 반환된다.
| 해바라기반 | 9월 결석 | 10월 결석 |
|---|---|---|
| 신짱구 | 2 | 2 |
| 김철수 | 1 | 3 |
| 한유리 | 2 | |
| 이훈이 | 1 | |
| 맹구 | 1 | 1 |
순서가 맞지 않아도 연산이 되는지 확인하기 위해 코드에서는 순서를 섞었다.
S4 = pd.Series([2, 1, 1],
index=['신짱구', '김철수', '맹구'],
name = '결석 수(9월)')
S5 = pd.Series([1, 2, 3, 1, 2],
index=['이훈이', '신짱구', '김철수', '맹구', '한유리'],
name = '결석 수(10월)')
S6 = S4 + S5
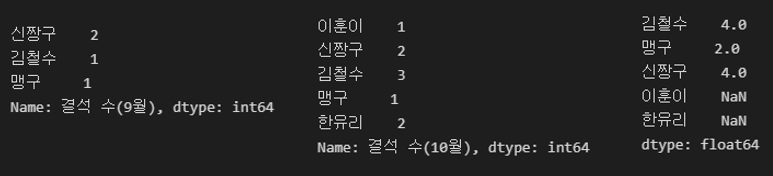
NaN은 Not a Number라는 뜻이다.NaN값은 float 자료형에서만 연산이 가능하기 때문에 이를 주의해야 한다.
NaN 다루기
series.notnull():NaN값이면False아니면True로 출력한다.
S6[S6.notnull()]
김철수 4.0
맹구 2.0
신짱구 4.0
dtype: float64
Reference
- Pandas, link: https://pandas.pydata.org/docs/user_guide/


댓글남기기