
[Python Note] 판다스(Pandas) 이해하기 (2)
1. 데이터프레임(Dataframe) 생성
데이터프레임(Dataframe) Class는 시리즈(Series)를 여러 개 합친 것이다.
정리하면 1차원 배열에 대한 데이터는 시리즈(Series)이고 2차원 배열에 대한 데이터는 데이터프레임(Dataframe)이다.
pd.DataFrame(a, index='index.name', coloumns='columns.name',
name='name', dtype='dtype')
- 이때
a는 2차원 배열(np.array) 또는 딕셔너리(dictionary)로 표현이 가능하다. df.index로 데이터프레임의 인덱스를 출력/설정할 수 있다.df.columns로 데이터프레임의 열 이름을 출력/설정할 수 있다.df.name으로 데이터프레임의 이름을 출력/설정할 수 있다.df.index.name으로 데이터프레임의 인덱스 이름을 출력/설정할 수 있다.df.columns.name으로 데이터프레임의 열 이름을 출력/설정할 수 있다.
다음 예제는 최근 컴백한 아이돌의 이름을 참고하여 임의로 만들었다.
| 이름 | 국어 | 수학 | 영어 | 과학 |
|---|---|---|---|---|
| 사쿠라 | 98 | 79 | 53 | 84 |
| 김채원 | 92 | 63 | 98 | 89 |
| 허윤진 | 71 | 59 | 50 | 60 |
| 카즈하 | 93 | 73 | 52 | 84 |
| 홍은채 | 85 | 80 | 53 | 68 |
1) 배열(np.array)로 만들기
- 배열을 행렬이라고 생각했을 때의 행과 열이 그대로 출력된다.
- 열 중에 하나를 인덱스로 설정하고 싶을 때에는
df.set_index()를 사용한다.
그러면 해당 열 이름이index.name이 된다. ※ 이때df.set_index()는 출력할 뿐df에 저장되지는 않는다.
df에 저장하고 싶을 때에는 다시 덮어씌워야 한다.
arr = np.array([['사쿠라', 98, 79, 53, 84],
['김채원', 92, 63, 98, 89],
['허유진', 71, 59, 50, 60],
['카즈하', 93, 73, 52, 84],
['홍은채', 85, 80, 53, 68]])
df = pd.DataFrame(arr)
df.columns = ['이름','국어','수학','영어','과학']
df
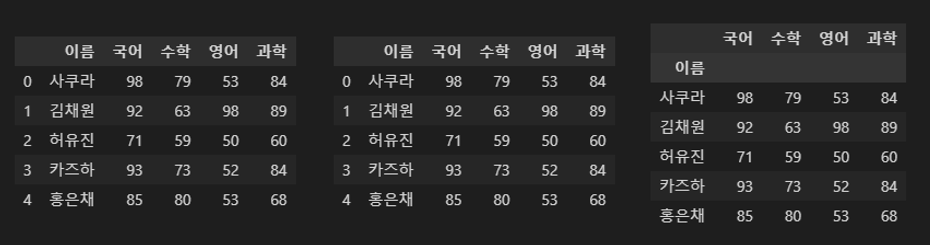
df.set_index('이름')
df
df = df.set_index('이름')
df
2) 딕셔너리(dictionary)로 만들기
key가 열 이름이 된다.
mydict = {
'사쿠라' : [98, 79, 53, 84],
'김채원' : [92, 63, 98, 89],
'허윤진' : [71, 59, 50, 60],
'카즈하' : [93, 73, 52, 84],
'홍은채' : [85, 80, 53, 68]
}
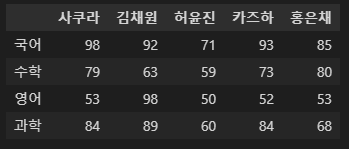
df = pd.DataFrame(mydict)
df.index = ['국어','수학','영어','과학']
df
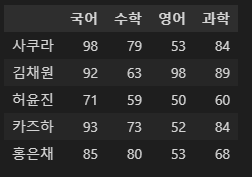
- 만약 행과 열을 바꾸고 싶을 때에는
numpy에서 배웠던 전치행렬(.T)을 사용한다.
2. 데이터프레임 입출력
- csv, excel, html, json 등 많은 포맷을 지원한다.
이 중 가장 많이 쓰이는 csv, excel, txt, html에 대해서만 소개한다.
| 이름 | 국어 | 수학 | 영어 | 과학 |
|---|---|---|---|---|
| 사쿠라 | 98 | 79 | 53 | 84 |
| 김채원 | 92 | 98 | 89 | |
| 허윤진 | 71 | 59 | 50 | 60 |
| 카즈하 | 93 | 73 | 84 | |
| 홍은채 | 80 | 53 | 68 |
1) 저장하기
직접 써서 저장
%%writefile 파일이름으로 간단히 파일을 생성할 수 있다.- 구분값을
,(쉼표)로 해서 위의 표를midterm.csv파일로 만들어보자.
%%writefile temp/midterm.csv
이름,국어,수학,영어,과학
사쿠라,98,79,53,84
김채원,92,,98,89
허윤진,71,59,50,60
카즈하,92,73,,84
홍은채,,80,53,68
‘midterm.csv’
이름,국어,수학,영어,과학
사쿠라,98,79,53,84
김채원,92,,98,999
허윤진,71,999,50,60
카즈하,92,73,,84
홍은채,,80,53,68
데이터프레임을 저장
.to_에 불러오고 싶은 포맷을 입력해서 저장한다.- ex.
df.to_csv('data.csv', sep='\t')
- ex.
- 인덱스, 컬럼명, 값이 모두 저장된다.
- 먼저
midterm.csv파일을 읽은 후 그 데이터테이블을midterm.txt파일로 다시 저장해보자.
이때 구분값은\t으로 설정하자.
※ 저장할 때 txt파일은.to_csv로 가능하다. - 저장할 때 결측값을
na_rep옵션을 통해 다른 값으로 표현해서 저장할 수 있다.
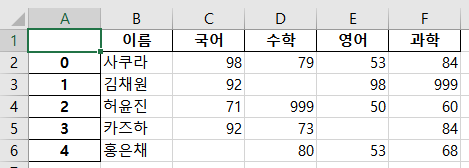
df = pd.read_csv('midterm.csv', sep=',')
df.to_csv('midterm.txt', sep='\t', na_rep='missing')
df.to_excel('midterm.xlsx')
‘midterm.txt’
이름 국어 수학 영어 과학
0 사쿠라 98.0 79.0 53.0 84
1 김채원 92.0 missing 98.0 999
2 허윤진 71.0 999.0 50.0 60
3 카즈하 92.0 73.0 missing 84
4 홍은채 missing 80.0 53.0 68
‘midterm.xlsx’
2) 읽어오기
- 모듈 불러오기
import pandas as pd pd.read_에 불러오고 싶은 포맷을 입력해서 불러온다.- 값이 써져 있지 않은 셀의 값은
NaN으로 표시된다.
만약 결측값이 다른 값으로 표현되었다면na_values옵션으로 미리 설정할 수 있다. - 옵션
index_col을 통해 인덱스를 미리 설정할 수 있다.- ex.
pd.read_csv('data.csv', index_col='c1', sep=',')
- ex.
- 보여질 데이터가 너무 많은 경우
df.head(n)또는df.tail(n)을 통해n을 설정해서 몇 개만 보이게 할 수 있다.
처음과 끝을 모두 보고 싶다면pd.set_option('display.max_rows', n)으로n을 설정해도 된다.
앞으로 더 많고 복잡한 데이터를 불러올 일이 많은데 내 마음대로 읽어지지 않는 경우가 많다.
.set_index()와columns를 이용해서 정리하는 연습이 필요하다.
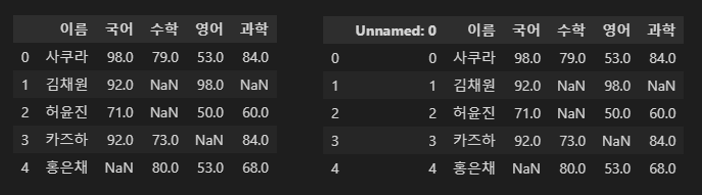
pd.read_csv() / pd.read_table()
- 먼저
midterm.csv,midterm.txt파일을 읽어보자.
이때 999와 공백은 결측인 부분이므로 모두NaN으로 표시하자.
df = pd.read_csv('temp/midterm.csv', sep=',', na_values=[999,' '])
df
df = pd.read_table('temp/midterm.txt', sep='\t', na_values=[999,' '])
df
pd.read_html()
- 웹에서 표 형식으로 되어 있는 내용을 데이터프레임으로 하고 싶을 때 사용한다.
- 웹에서 정보를 가져올 때에는 인코딩(encoding)에 매우 주의해야 한다.
한글의 경우 보통encoding='utf-8'또는encoding='CP949'로 해결된다. - 해당 웹페이지에 보이는 표 하나가 리스트에 하나의 문자열(string)으로 저장된다.
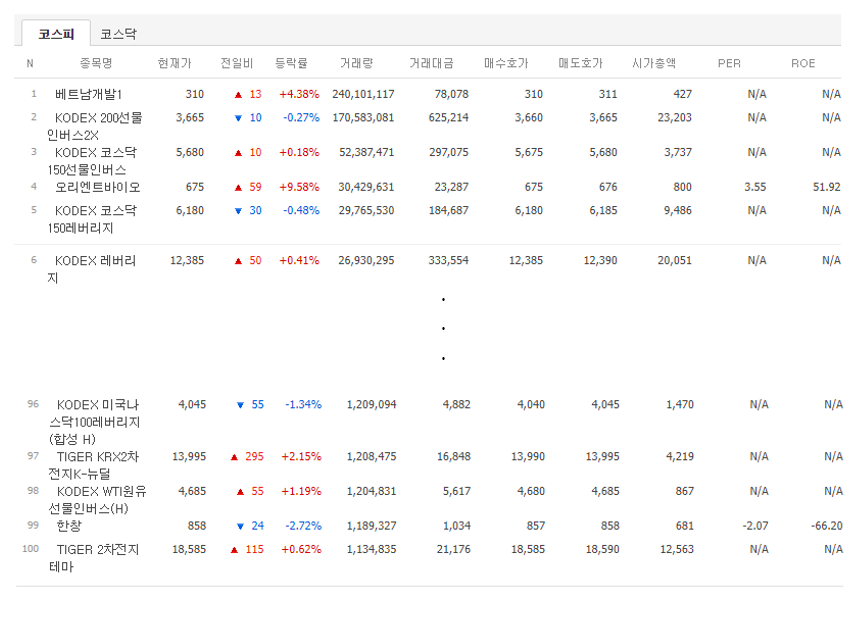
- 네이버 금융 사이트에서 거래 상위 종목 데이터를 읽어오자.
(네이버 금융)
- STEP 1.
df = pd.read_html()을 통해 데이터를 읽는다. - STEP 2.
len(df)로 테이블이 몇 개 있는지 확인한다. - STEP 3. 내가 원하는 테이블이 어느 위치에 있는지 파악하고 저장한다.
- STEP 4. 보기 좋게 인덱스, 컬럼명 등을 설정한다.
- STEP 1.
STEP 1 ~ STEP 3 (Click!)
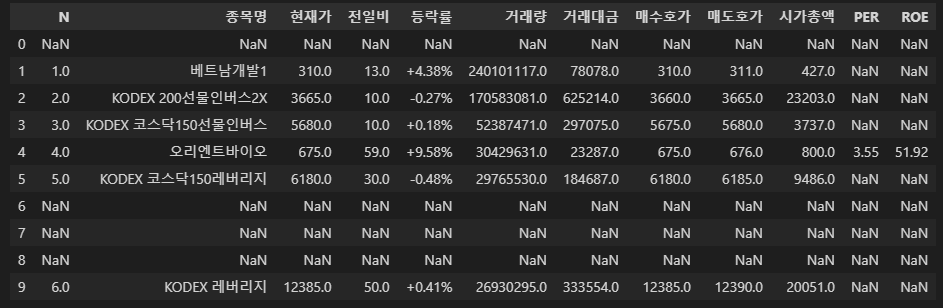
# STEP 1. 데이터 읽기
df = pd.read_html('https://finance.naver.com/sise/sise_quant.naver', encoding='CP949')
# STEP 2. 읽은 테이블 개수 확인
len(df)
# STEP 3. 내가 원하는 테이블 찾기
df_financial = df[1]
df_financial.head(10)
- 웹 상에서 선이 그어지는 곳마다 전체 셀 값이
NaN이 생성되는 것 같다.
전체가NaN인 행의 값은 지우자.Tip!
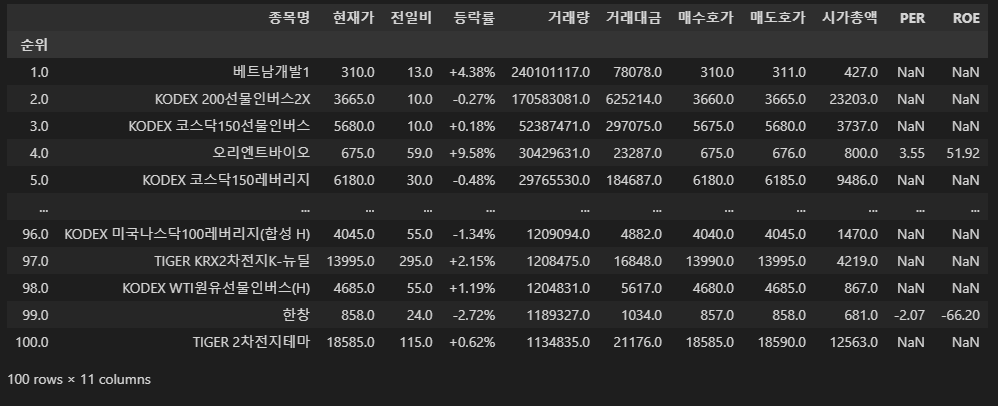
전체가 결측(NaN)인 행 또는 열을 삭제하고 싶을 때에는df.dropna(how='all')을 사용한다. N열을 인덱스로 지정한 후 이름을'순위'로 바꾸자.
STEP 4 (Click!)
# 1. 전채 NaN인 행 또는 열 제거
df_financial = df_financial.dropna(how='all')
# 2. 인덱스 설정, 이름 바꾸기
df_financial = df_financial.set_index('N')
df_financial.index.name = '순위'
df_financial
Reference
- Pandas, link: https://pandas.pydata.org/docs/user_guide/


댓글남기기